Data Pipeline Là Gì? Tìm Hiểu Về Data Pipeline Platform
Data Pipeline Là Gì?
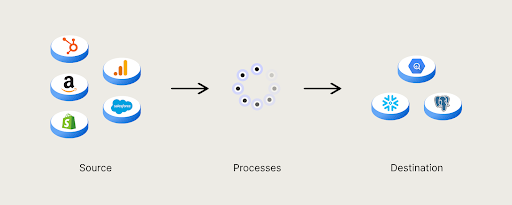
Data pipeline (đường ống dữ liệu) là một hệ thống tự động hóa quá trình di chuyển và chuyển đổi dữ liệu từ nhiều nguồn khác nhau đến đích cuối cùng, giúp xử lý dữ liệu một cách nhanh chóng và hiệu quả. Đây là một phần quan trọng trong hệ thống quản lý dữ liệu hiện đại, đặc biệt trong các ứng dụng liên quan đến phân tích dữ liệu và trí tuệ nhân tạo (AI).
Data Pipeline Là Gì?
Tầm Quan Trọng Của Data Pipeline
- Tự động hóa quá trình xử lý dữ liệu: Giúp giảm thiểu sai sót do con người và tối ưu hóa hiệu suất làm việc.
- Hợp nhất dữ liệu từ nhiều nguồn: Hỗ trợ thu thập dữ liệu từ nhiều hệ thống khác nhau như cơ sở dữ liệu, API, tệp log, dịch vụ đám mây.
- Tăng tốc phân tích dữ liệu: Cung cấp dữ liệu sạch và có cấu trúc để hỗ trợ ra quyết định kinh doanh nhanh chóng.
- Tối ưu hóa tài nguyên: Giảm tải cho hệ thống bằng cách xử lý dữ liệu theo từng giai đoạn thay vì xử lý trực tiếp.
- Cải thiện khả năng mở rộng: Data pipeline giúp hệ thống dễ dàng mở rộng khi dữ liệu ngày càng lớn.
Các Thành Phần Chính Của Data Pipeline
Một data pipeline thường bao gồm các thành phần sau:
Nguồn Dữ Liệu (Data Sources)
Nguồn dữ liệu có thể đến từ nhiều nơi khác nhau như:
- Cơ sở dữ liệu quan hệ (MySQL, PostgreSQL, SQL Server)
- Hệ thống lưu trữ đám mây (Amazon S3, Google Cloud Storage)
- API của các nền tảng khác nhau
- Tệp log hệ thống
Quá Trình Trích Xuất, Chuyển Đổi Và Tải Dữ Liệu (ETL – Extract, Transform, Load)
- Extract (Trích xuất): Thu thập dữ liệu từ các nguồn khác nhau.
- Transform (Chuyển đổi): Làm sạch, chuẩn hóa và biến đổi dữ liệu thành định dạng có thể sử dụng.
- Load (Tải dữ liệu): Đưa dữ liệu vào kho dữ liệu hoặc hệ thống phân tích.
Lưu Trữ Dữ Liệu (Data Storage)
- Kho dữ liệu truyền thống như data warehouse (Snowflake, Google BigQuery, Amazon Redshift).
- Hệ thống lưu trữ dữ liệu phi cấu trúc như data lake (AWS Lake Formation, Azure Data Lake).
- Hệ thống lưu trữ NoSQL (MongoDB, Cassandra) giúp xử lý dữ liệu phi cấu trúc linh hoạt.
Xử Lý Dữ Liệu (Data Processing)
- Hệ thống xử lý thời gian thực (Apache Kafka, Apache Flink).
- Hệ thống xử lý theo lô (Apache Spark, Hadoop).
- Các công cụ tích hợp AI/ML để phân tích dữ liệu nâng cao.
Công Cụ Phân Tích Và Trực Quan Hóa
- Tableau, Power BI, Looker giúp hiển thị dữ liệu dưới dạng biểu đồ và báo cáo.
- Google Data Studio hỗ trợ trực quan hóa dữ liệu miễn phí cho các doanh nghiệp nhỏ.
Các Loại Data Pipeline
- Batch Processing Pipeline (Xử Lý Theo Lô): Dữ liệu được thu thập, xử lý và tải lên theo các khoảng thời gian định sẵn (hàng giờ, hàng ngày, hàng tuần). Thích hợp cho báo cáo tài chính, phân tích dữ liệu lịch sử.
- Streaming Data Pipeline (Xử Lý Dữ Liệu Thời Gian Thực): Xử lý dữ liệu liên tục ngay khi chúng phát sinh. Ứng dụng trong hệ thống giám sát, phát hiện gian lận, AI/ML.
- Hybrid Data Pipeline (Kết Hợp): Kết hợp cả xử lý theo lô và thời gian thực để tối ưu hóa hiệu suất. Phù hợp với doanh nghiệp cần phân tích dữ liệu tức thì nhưng vẫn duy trì khả năng tổng hợp theo lô.
Các Nền Tảng Data Pipeline Phổ Biến
- Apache Airflow: Công cụ quản lý workflow giúp tự động hóa quy trình ETL.
- AWS Data Pipeline: Dịch vụ của Amazon hỗ trợ tích hợp và xử lý dữ liệu trên nền tảng AWS.
- Google Cloud Dataflow: Cung cấp khả năng xử lý dữ liệu mạnh mẽ theo thời gian thực.
- Azure Data Factory: Công cụ giúp tích hợp dữ liệu từ nhiều nguồn trên Microsoft Azure.
- Prefect: Giải pháp thay thế Apache Airflow với giao diện trực quan hơn.
Cách Xây Dựng Data Pipeline Hiệu Quả
- Xác Định Mục Tiêu: Xác định loại dữ liệu cần xử lý và mục đích sử dụng. Đánh giá nhu cầu xử lý theo lô hay thời gian thực.
- Chọn Công Cụ Phù Hợp: Sử dụng ETL hoặc ELT phù hợp với yêu cầu hệ thống. Kết hợp công cụ mã nguồn mở và dịch vụ đám mây để tối ưu chi phí.
- Đảm Bảo Tính Chính Xác Và Bảo Mật Dữ Liệu: Xác thực dữ liệu trước khi tải vào hệ thống. Bảo vệ dữ liệu bằng mã hóa và phân quyền truy cập. Thực hiện backup định kỳ để tránh mất mát dữ liệu.
- Tối Ưu Hiệu Suất: Tận dụng kiến trúc phân tán để tăng tốc độ xử lý. Loại bỏ dữ liệu trùng lặp và không cần thiết để giảm tải cho hệ thống.
Kết Luận
Data pipeline đóng vai trò quan trọng trong việc xử lý và quản lý dữ liệu hiệu quả. Nó giúp doanh nghiệp tối ưu hóa quy trình thu thập, chuyển đổi và phân tích dữ liệu, từ đó hỗ trợ ra quyết định chính xác. Việc lựa chọn nền tảng phù hợp và thiết kế một hệ thống data pipeline hiệu quả sẽ giúp tối ưu tài nguyên và nâng cao hiệu suất hoạt động.
Việc xây dựng một hệ thống data pipeline linh hoạt và mạnh mẽ sẽ giúp doanh nghiệp tăng cường khả năng khai thác dữ liệu, cải thiện quá trình ra quyết định và tận dụng tối đa giá trị từ dữ liệu. Với sự phát triển của công nghệ, các nền tảng data pipeline ngày càng hiện đại hơn, cho phép xử lý dữ liệu nhanh chóng, an toàn và chính xác hơn.
ĐỌC THÊM:
Data Model Là Gì? Tìm Hiểu Về Modelling
Sơ Đồ ERD Là Gì? Hướng Dẫn Cách Vẽ Sơ Đồ ERD
Tổng Quan Hệ Quản Trị Cơ Sở Dữ Liệu Là Gì?
Biến là gì? Các loại biến phổ biến cần biết
Trực Quan Hóa Dữ Liệu – Hành Trang Trong Thời Đại Số