| Phần mềm - Dịch vụ | Bảng giá |
|
Giỏ hàng trống |
HOTLINE: 0833052299

21/04/2025 | Tran Van Dao
Trong thời đại dữ liệu bùng nổ, doanh nghiệp cần một phương thức lưu trữ và phân tích linh hoạt, mạnh mẽ để khai thác toàn bộ giá trị từ dữ liệu. Chính vì thế, data lake đã trở thành xu hướng phổ biến. Nhưng data lake là gì, nó có gì khác biệt so với data warehouse, và vì sao nhiều doanh nghiệp lại lựa chọn mô hình này? Bài viết sau đây sẽ giúp bạn giải mã khái niệm, ứng dụng và sự khác biệt giữa hai nền tảng dữ liệu quan trọng này trong thế giới hiện đại.
Data lake (Hồ dữ liệu) là một kho lưu trữ tập trung, nơi bạn có thể lưu trữ mọi loại dữ liệu: có cấu trúc (structured), bán cấu trúc (semi-structured), và phi cấu trúc (unstructured) – như log máy chủ, ảnh, video, dữ liệu IoT hoặc dữ liệu từ mạng xã hội. Dữ liệu được lưu trữ ở định dạng gốc, chưa qua xử lý, và chỉ được phân tích khi cần thiết (schema-on-read).
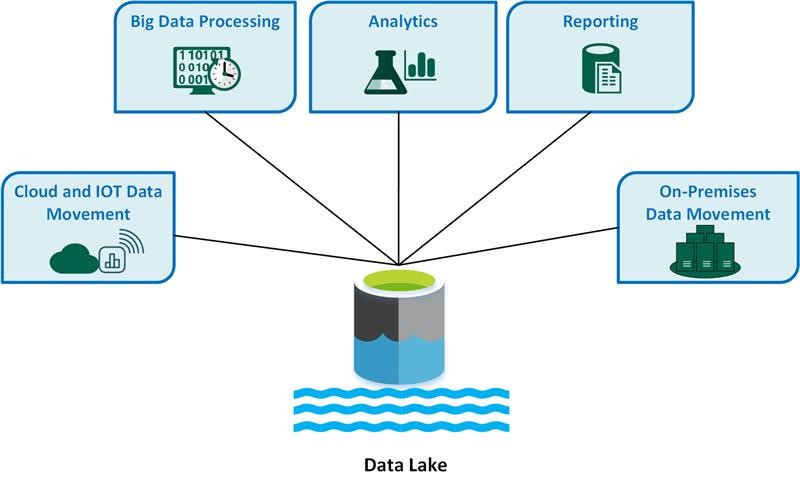
Data Lake là gì?
Hồ dữ liệu cho phép doanh nghiệp thu thập và phân tích dữ liệu khổng lồ theo thời gian thực mà không cần cấu trúc hóa trước – một ưu điểm lớn so với kho dữ liệu truyền thống.
Data warehouse là kho dữ liệu truyền thống, lưu trữ dữ liệu đã được xử lý, làm sạch và cấu trúc (schema-on-write). Nó phù hợp với các báo cáo kinh doanh định kỳ, phân tích lịch sử và truy vấn có cấu trúc cao.
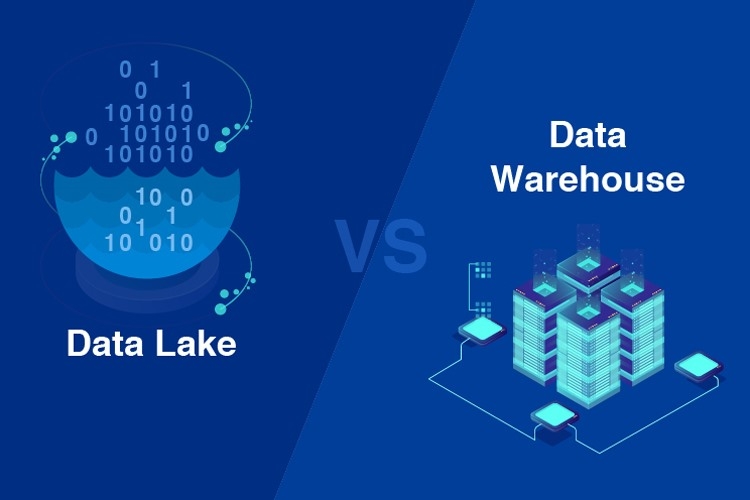
Sự khác biệt giữa Data Lake và Data Warehouse
| Tiêu chí | Data Lake | Data Warehouse |
| Loại dữ liệu | Có thể lưu trữ mọi loại dữ liệu | Chủ yếu dữ liệu đã cấu trúc |
| Cách xử lý dữ liệu | Schema-on-read | Schema-on-write |
| Chi phí | Thường rẻ hơn vì lưu dữ liệu thô | Cao hơn do xử lý và lưu trữ dữ liệu sạch |
| Tốc độ triển khai | Nhanh, do không cần xử lý trước | Chậm hơn do cần ETL |
| Linh hoạt | Cao, thích hợp với AI, ML, big data | Hạn chế, chủ yếu phục vụ báo cáo |
| Người dùng chính | Data scientist, kỹ sư dữ liệu | Nhà phân tích, quản lý cấp cao |
Kiến trúc data lake thường bao gồm các lớp chính sau:
Tập hợp dữ liệu từ nhiều nguồn như ứng dụng, IoT, mạng xã hội… Dữ liệu được đưa vào raw zone của data lake.
Lưu trữ dữ liệu dưới định dạng thô (raw), xử lý (curated) và dữ liệu phân tích (consumption).
Xử lý và chuyển đổi dữ liệu, thường sử dụng Spark, Hive hoặc các công cụ ETL hiện đại.
Kết nối với các công cụ như Power BI, Tableau, Jupyter Notebook hoặc các công cụ AI để phân tích dữ liệu.
Bao gồm phân quyền truy cập, mã hóa dữ liệu, quản trị chất lượng và kiểm soát dữ liệu theo tiêu chuẩn data governance.
Phân tích hành vi người dùng: Kết hợp dữ liệu từ website, ứng dụng, CRM để phân tích toàn diện hành vi khách hàng.
Mặc dù data lake mang lại nhiều lợi ích, nhưng cũng đi kèm không ít thách thức:
Data lake đang ngày càng trở thành một phần không thể thiếu trong chiến lược dữ liệu của doanh nghiệp hiện đại. Với khả năng lưu trữ linh hoạt, hỗ trợ phân tích nâng cao và khả năng tích hợp tốt với các công nghệ mới như AI, IoT, data lake analytics, nó mở ra cơ hội khai phá toàn bộ tiềm năng dữ liệu. So với data warehouse, data lake vs cung cấp sự linh hoạt và tiết kiệm chi phí vượt trội, đặc biệt trong các trường hợp xử lý big data (data lake vs big data).
Nếu doanh nghiệp bạn đang hướng tới một nền tảng dữ liệu mạnh mẽ, thích ứng với tương lai, đã đến lúc cân nhắc xây dựng hoặc tích hợp data lake vào hạ tầng dữ liệu. Hãy bắt đầu từ hôm nay để không bỏ lỡ lợi thế cạnh tranh từ sức mạnh của dữ liệu!
ĐỌC THÊM:
Dịch vụ triển khai Power Bi – BHK
Power BI và Microsoft Planner – Tăng cường quản lý dự án
Hotline